
前言
目前,每到各种节假日和营销事件出现的时候,朋友圈会转发各种H5,比如2018年底的年终总结类的,其他时候各种测评类的,以及商家为营销做的各种趣味游戏类的.公司也做了大量的H5,累计了大量的数据,这些数据应该如何产生价值?
1.通过H5可以获得什么数据?
H5是移动互联网时代重要的传播形式,通过它,可以累计的足够多的数据(包括用户之间的阅读,分享,转发等).根据经验,我们不难得出下面的结论
- 根据用户之间的转发关系和分享链,可以发掘出每一场传播中的KOL是哪些人群;
- 根据每个H5的转发总量,可以知道信息最终传达到多少用户手中;
- 而根据不同时间段的阅读次数,可以得到用户使用移动设备的高低峰时间,从而指导我们在正确的时间去发送和传播内容;
- 分析用户的地区,设备品牌,型号,使用场景,用户性别等数据可以制订出更加精准的内容和营销策略,进一步提升效率….
2.关于数据可视化
目前开发人员经常接触和使用的一般是Echarts 和 highcharts 两款js插件,文档都比较齐全,使用比较方便.不仅能渲染柱状图,折线图.饼状图等基本图表,还可以渲染更高级的内容



echarts 和 highcharts 使用方法大同小异,都是在页面中引用库文件,同时提供对应格式的数据进行初始化并且执行渲染.
简单的使用例子:
<script src="https://cdn.bootcss.com/echarts/4.2.0-rc.2/echarts.min.js"></script>
<div id="main" style="width:auto;height:300px;"></div>
<script>
{{--绘制图表,初始化数据--}}
echarts.init(document.getElementById('main')).setOption({
series: {
type: 'pie',//选择类型
data: [
{name: 'A', value: 1212},//提供数据
{name: 'B', value: 2323},
{name: 'C', value: 1919}
]
}
});
</script>而我们目前在项目中使用的基本是通过PHP查询数据表中数据,整理成如上述代码中的data参数所需要的格式,并且在整个个页面加载前就直接转换为json并直接在页面保存,供js使用
3.关于后台处理逻辑
目前H5统计项目原理:

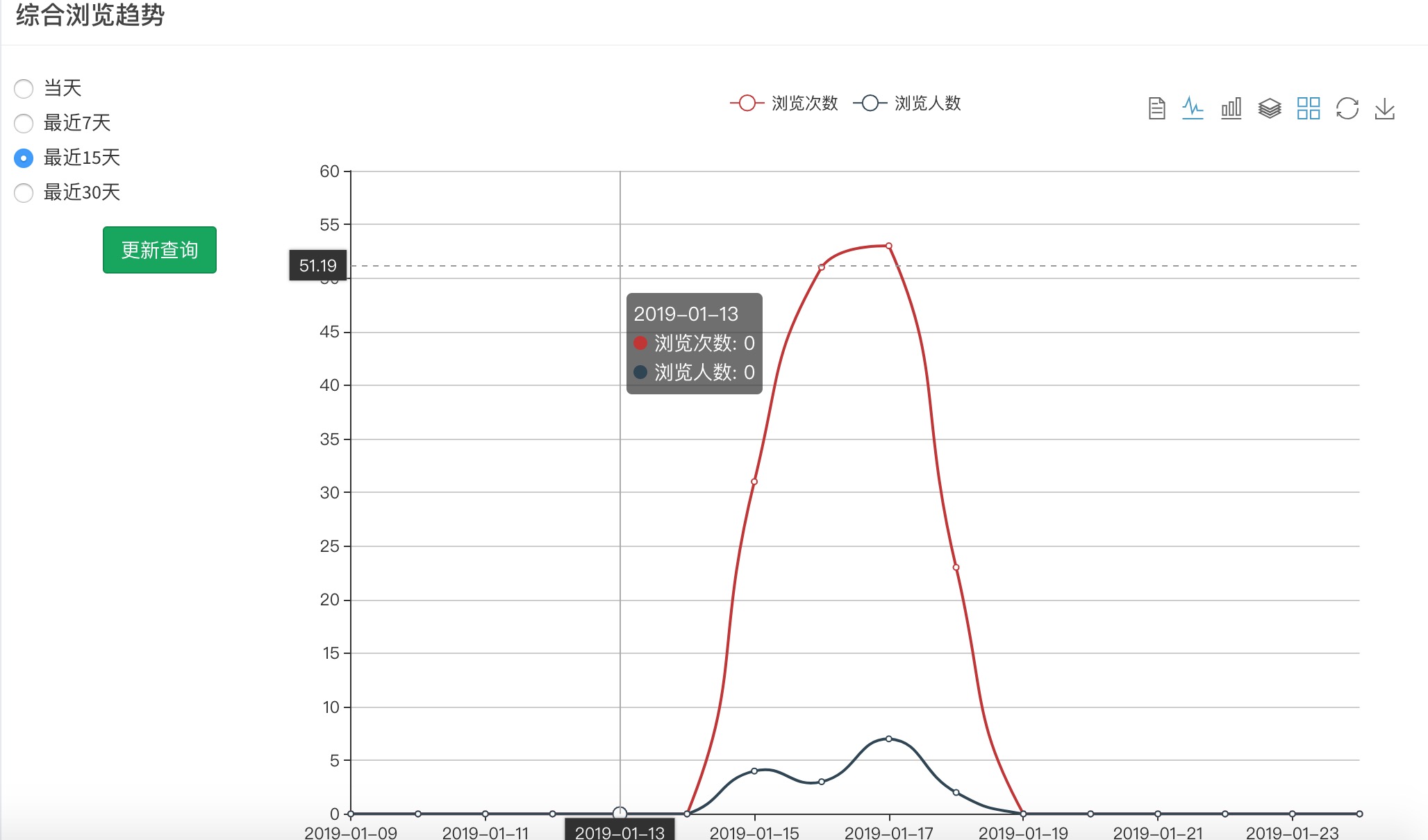
(1).综合浏览趋势
综合浏览趋势数据主要为查询表中指定H5_id,且类型为浏览的结果,并根据时间进行分类,最终将结果返回页面
综合浏览趋势数据:
(2)综合传播渠道
综合传播渠道目前统计前5级(0~4)传播量,做了两个处理方案:
–1.前端处理,原链接URL不带有传播层级参数,用户主动浏览,属于第0级传播,请求接口时传参level=0;当用户进行分享时,检测当前链接中是否带有level参数(level在URL中混淆加密处理),若有则level+=1,否则level=1,以此类推,减轻服务器处理的压力;
–2.后端处理,每小时自动运行,后端对数据表中的分享记录进行递归处理,查询指定H5_id的记录,根据用户openid分组去重,和若没有父级节点,则当前传播为第0级传播,若有父级节点,则再查询相同H5_id且openid=父级节点的记录,以此类推,假如查询了三层父节点时停止,则表示当前传播为第3级….这种方式随着数据量的提升,运算规模会变为N的N次方的N次方…容易导致内存溢出,因此目前使用的是第一种方案
(3)综合分享去向
这里比较简单,根据分享类型查询数据,并且去重即可
(4)综合分享关系
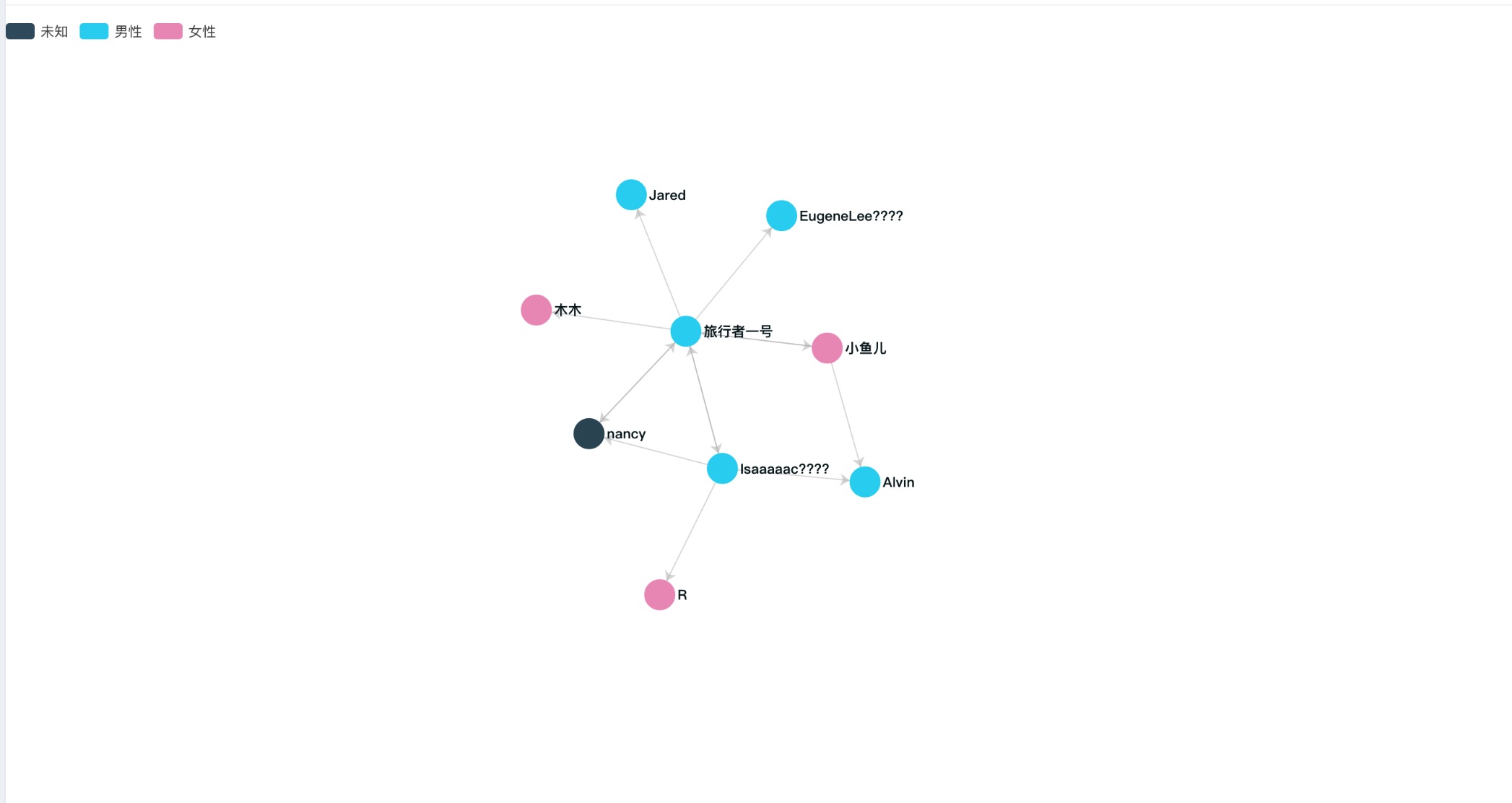
原理类似综合传播渠道,查询的时候还带上了用户之间的分享关系,同时带上了用户性别,分享数量等数据,位于中心点的向四周发送数据的点表示分享者,分享线条越多,该用户越可能是KOL,是传播该H5的关键用户
(5)pv地域分布
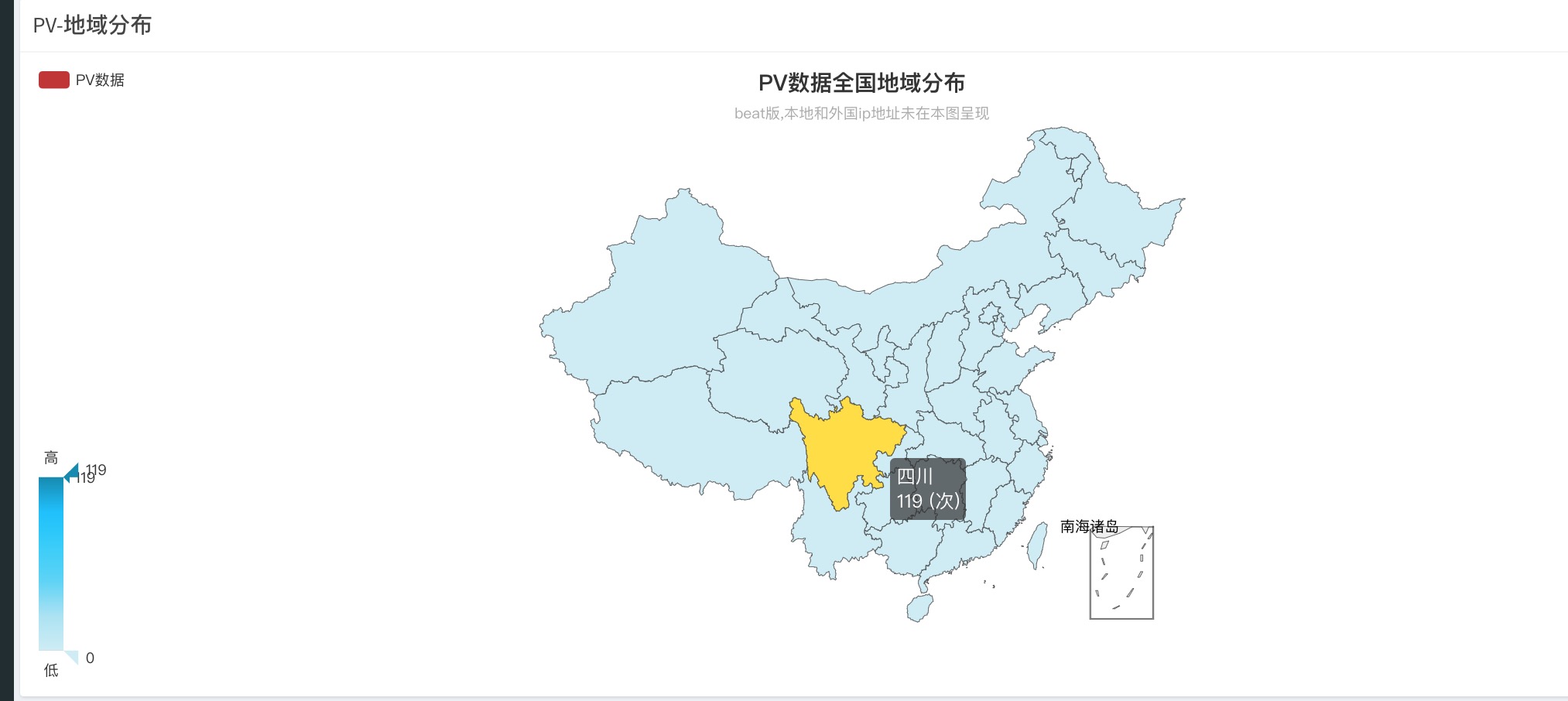
此处的数据是根据页面请求分享记录接口时,服务到获取到的ip地址进行处理而得来的用户地域分布,使用了纯真ip地址库解析出物理位置,并且渲染数据而得来
(6)用户设备品牌
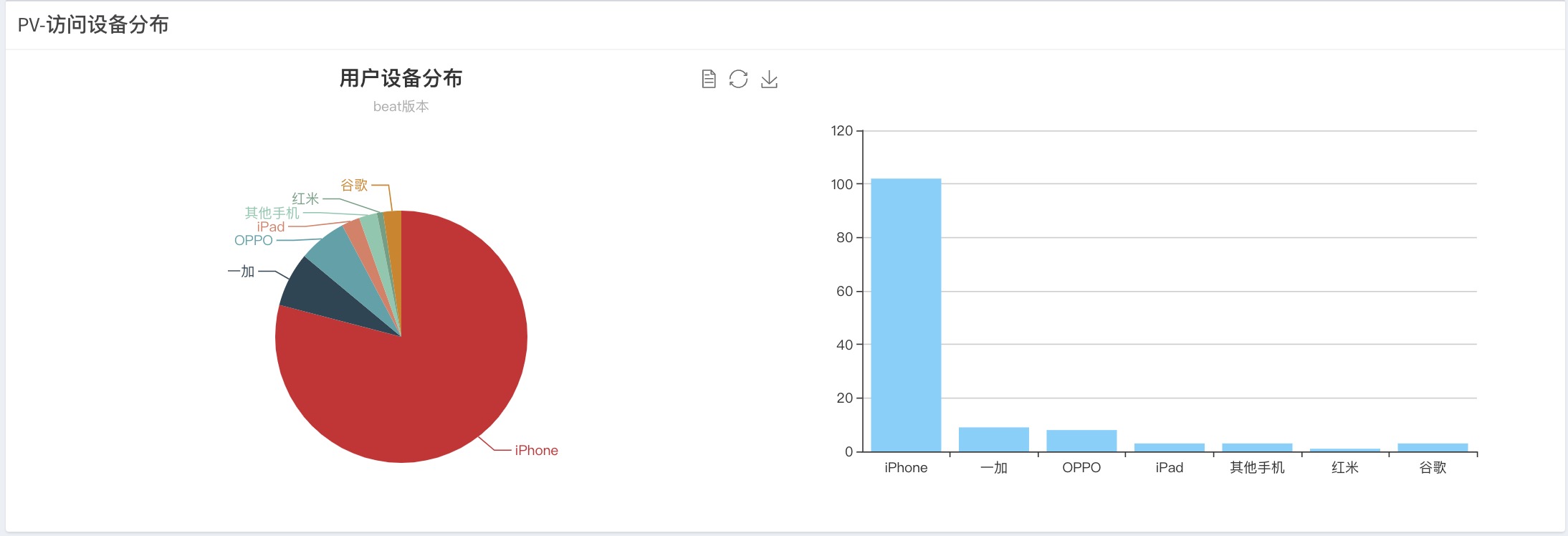
根据前端发送的user-agent信息匹配而来,目前识别的主流的手机品牌,其余未能识别的归入到其他品牌中
(7)用户性别分布

根据获取用户微信授权时拿到的基本数据得来
(8)用户设备操作系统和使用网络

获取方式同(6)
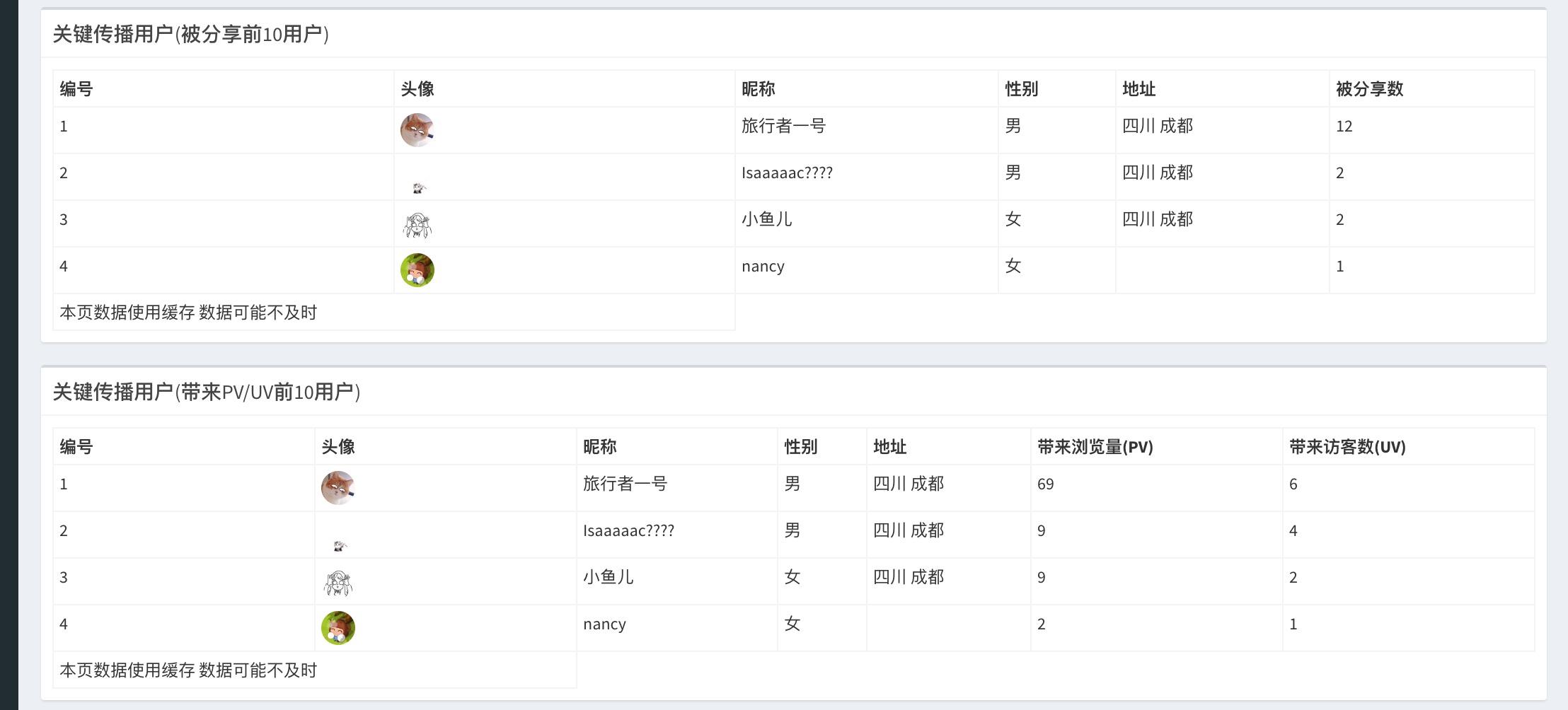
(9)关键传播用户
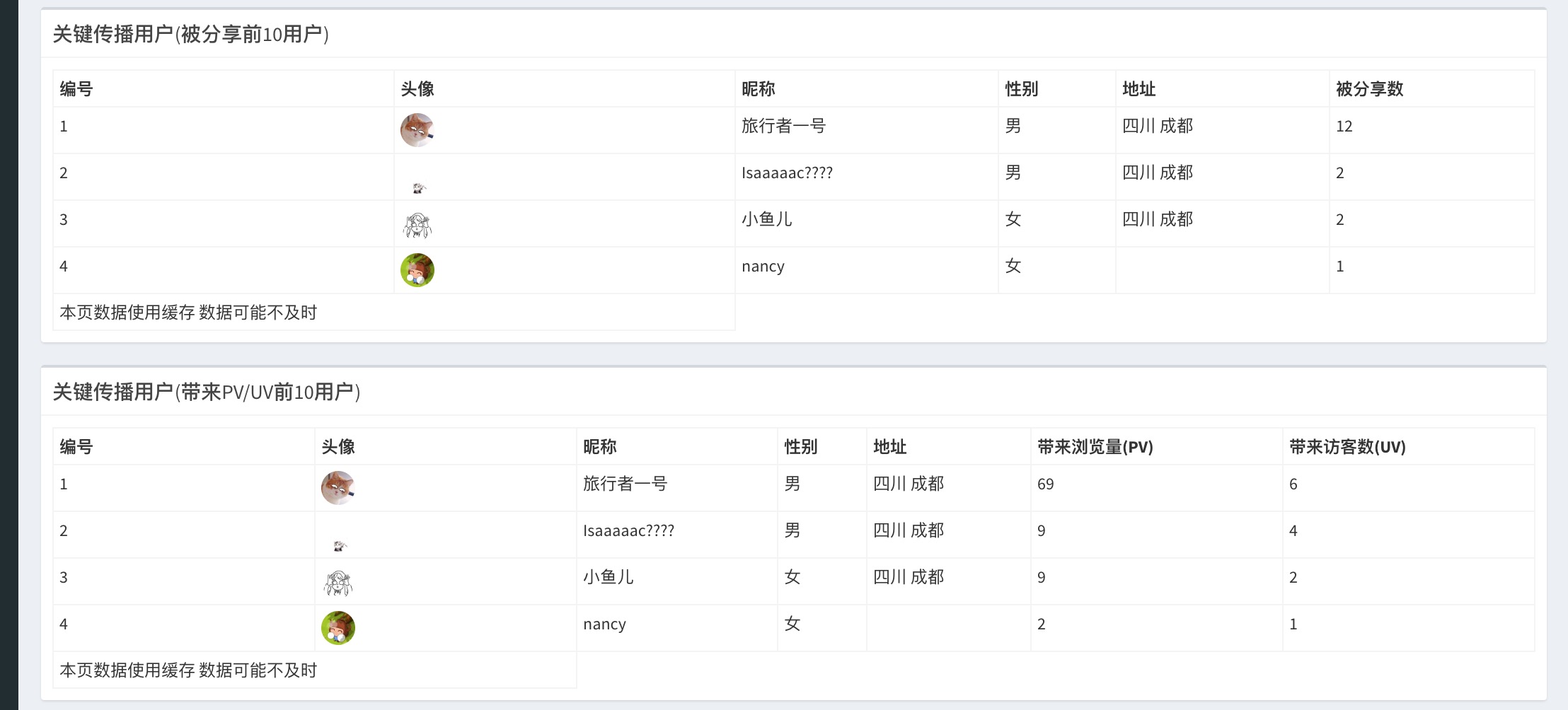
原理同传播渠道和分享关系类似,数据展示为表格化,包含用户基本信息和头像
4.关于对目前界面的优化建议
页面分页分部分处理;
H5pv/uv排行;
缺失数据的处理;
每一个H5统计中根据文章/H5的标签给KOL用户贴标签;